

FLUC - Frankenstein-Limes Universal Converter
The Frankenstein-Limes Universal Converter (FLUC) is the first product of the new FL5 infrastructure and provides all FLAM5 conversion options for original files. It reads original data from local or remote (SSH) sources, converts it into internal neutralized elements through our element interface and, after applying various conversions, the resulting elements are written in the desired output format to one or more local or remote targets.
FLUC reads and writes FLAMFILEs of version 4 and older. Thus, it is a replacement for the FLAM4 utility while all FLAM4-customers get the benefit of the new conversion options (HEX (Base16), Base32/64, OpenPGP (RFC4880), OpenSSL ENC, GZIP (RFC195x with ZEDC support), BZIP2, XZ, LZIP, ZSTD, TEXT/TABLE/XML formatting, ZIP/TAR archives, SSH support, anti virus scanning, ...) offered by FLAM5. By the integration of character set conversion (ASCII/EBCDIC/UNICODE (inclusive string.latin (XÖV, NPA) support, NFD/NFC normalisation, entry assistent, reporting, ...)) of all common checksum, encoding, compression, and encryption methods, of various physical file formats and the understanding of logical data contents we will continue to extend the range of options for converting original data. Thereby, FLAM will become a link between all open standards of the distributed world and many - partly proprietary - mainframe formats.
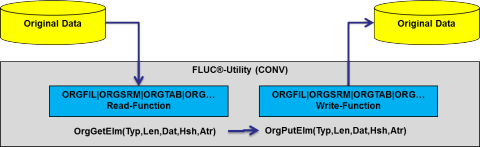
FLUC supports reading and writing files in many different modes:
- binary/block-oriented
- character-oriented
- text-oriented
- record-oriented
- FLAM4FILE (record-oriented)
- from ZIP or TAR archive
- locally or remote (per SSH)
- output to unlimted amount of targets at the same time
- and many more
Unlimited amount of conversions may follow upstream or downstream:
- Encodings: Base64/32/16(Hex)
- with optional ASCII/EBCDIC Armor (RFC4880)
- with optional CRC checksums (RFC4880)
- Encryption: FLAM, OpenPGP (RCF4880), OpenSSL ENC
- Compression: GZIP(RFC1950/51/52), BZIP2, XZ, LZIP, ZSTD
- Character conversion: ASCII, EBCDIC, UNICODE, String.Latin, NFD/NFC
- Checksum generation and verification (MD5/SHA1/SHA256/SHA512/SHA3)
- Signature generation and verification (OpenPGP)
- Anti virus scanning (including z/OS)
- and many more
The decomposition of data into elements depends on the type of data:
- Binary: data record/data block is mapped to a data element
- Text: data blocks are broken up by text delimiters into text records
- Table: records (table rows) are broken down to one element per column
- Conversion between FB/VB (fix and variable structures) and CSV/XML/JSON
- XML: data blocks are broken up into individual XML-elements (tag, attribute, value, ...)
- and many more
With this powerful tool you can, for example, use SSH to remotely read a UTF-16LE-encoded text document stored in a ZIP file under Windows, read it there in block mode and have it automatically decompressed. The document is automatically broken up into text records in UTF8 internally. When writing these text records to a VBA file the text records are implicitly converted to EBCDIC with automatic insertion of ASA control characters. For backup purposes, a PGP-encrypted copy can be written in Latin-1 with 0x0A as delimiter to remote ZIP archive. The JCL command for this would look as follows:
//CONV EXEC PGM=FLCL,PARM='CONV=DD:PARM' //STEPLIB DD DSN=FLAM.LOAD,DISP=SHR //SYSPRINT DD SYSOUT=* //SYSOUT DD SYSOUT=* //OUTFIL DD DSN=&SYSUID.DOCUMENT,DISP=(NEW,CATLG), // RECFM=VBA,LRECL=517,SPACE=(CYL,(10,20)) //PARM DD * read.text(file='ssh://@windows.server/myfiles.zip/?document.txt') write.record(file='DD:OUTFIL' report='.FLCL.REPORT') write.text(method=unix ccsid=latin1 file='ssh://user@server/my.zip' encr.pgp(pass=a'test') archive.zip()) /*
You can specify an unlimted amount of ouput (XCNV) or write (CONV) specifications. The same call with a small extension of the XCNV command looks like:
//XCNV EXEC PGM=FLCL,PARM='XCNV=DD:PARM'
//STEPLIB DD DSN=FLAM.LOAD,DISP=SHR
//SYSPRINT DD SYSOUT=*
//SYSOUT DD SYSOUT=*
//OUTFIL DD DSN=&SYSUID.DOCUMENT,DISP=(NEW,CATLG),
// RECFM=VBA,LRECL=517,SPACE=(CYL,(10,20))
//PARM DD *
input(sav.fil(fio.zip(name='ssh://@windows.server/myfiles.zip/?document.txt') cnv.zip() cnv.chr() fmt.txt()))
output (sav.file(fmt.txt(method=host) cnv.chr(report='.FLCL.REPORT') fio.rec(name='DD:OUTFIL')))
output(sav.file(fmt.txt(method=unix) cnv.chr(to=latin1) cnv.pgp(pass=a'test')
fio.zip(name='ssh://user@server/mybackup.zip')
fio.blk(name='~/my.pgp')
fio.blk(name='ssh://partner@server/his.pgp')))
/*
With the XCNV command you can additionally specify an unlimited amount of different I/O procedures (FIO[BLK(),ZIP(),FL4(),TXT()]). This is useful to store the same converted data stream at different locations. For example, you can write the same PGP file locally for later use, remotely for your partner and as member in a ZIP archive for backup purposes (see example above).
FLUC allows transforming on the host all kinds of formats from the distributed world into the appropriate record format. But also converting between different host file formats is possible. Since FLAM5 can manage arbitrary attributes for an element we break up an FBA/VBA or FBM/VBM record into the net data, their length, and possibly their control character. Now that the print-control character is no longer part of the record, you can, for example, transform an FBA to a VB file with the control character removed. You can also add or keep control characters or switch between ASA and machine control characters. With relative files (RRDS) we use attributes to mark gaps unambiguously. This allows transforming a relative file into a sequential data set in different ways. Beside RRDS, other VSAM file types can be loaded via FLUC from sequential data sets or unloaded into such. Also under UNIX or Windows many conversions are possible. For the example above, you would use the following command locally on windows
flcl conv read.text(file='myfiles.zip/?document.txt') write.text()
in order to have the same text output in the respective system-specific character set (Windows: Latin1; UNIX: UTF-8) with the correct delimiters (Windows: 0x0D0A; UNIX: 0x0A) as "document.txt". The system-specific character set is determined by the environment variable LANG which can be set on the host and the other platforms. One way to set it is via the FLCL configuration data.
When readin original data, FLAM can automatically recognize the type of character set (ASCII/EBCDIC/UTF-8/16/32) and its language recognition selects the matching codepage. In almost 100% the character code conversion is automatically done correctly. Only when we recognize EBCDIC on a German Windows-PC and IBM 1141 does not fit selecting the correct CCSID (codepage) must be done manually.
The following little example illustrates with a possible scenario the remarkable capabilities of FLUC. It can also save very much CPU time and improve security because many conversions can be done in the same run without use of temporary files or additional tools.
It may occur that a file is read in binary blocks from a remote source, verify a MD5 checksum, then undergoes BASE64-decoding followed by PGP-decryption (RFC4880), and is then decompressed by RFC1951/52 (GZIP) and a second checksum verified, in a subsequent action a character set conversion with transliteration may be done and delimiter-based text records created. While they are written, records can be added print-control and padding characters and stored as an FBA file with separate a SHA1 checksum in a FLAM4FILE. All this can be done in one step without touching a byte more than once.
Moreover, reading can be done locally or remotely on one platform while writing can take place remotely or locally on different ones. Additional you can convert the data streams or record lists between different table formats (FIX, VAR, CSV, TLV, TVD, XML, JSON, ...).
With our pre- and post-processing, preparatory actions and follow-up processes can be initiated globally or per file, locally or remotely. This allows, for example, to transfer a file via SSH to the USS of an IBM mainframe and then to copy it as a post process into a MVS dataset and, if this was successful, to delete the USS file. Another example would be the implementation of an acknowledgement procedure during the file transfer, where a checksum over the original is calculated in pre-processing and this is also done on the remote side in post-processing after the transfer and the two checksums are compared locally in a further post-processing step.
*Example 16:* Binary copy of a file per SSH to a remote system, with
checksum calculation over the local original file as pre-process and
over the copied remote file as post process and a final post processing
which compares the check sums. This could be used for example to realize
a receipt for an data transfer.
------------------------------------------------------------------------
flcl xcnv
input(save.file(
fio.blk(file=wrtorg.bin
pre(command='sha1sum [copy]'
stdout=wrtorg.local.sha1))
))
output(save.file(
fio.blk(file=ssh://:limes@tests.limes.de/wrtorg.bin
pst(command='sha1sum [copy]'
stdout=wrtorg.remote.sha1))
pst(command='diff wrtorg.local.sha1 wrtorg.remote.sha1'
stdout=log)))
------------------------------------------------------------------------
*Example 17:* Binary copy of a file per SSH to a IBM mainframe system
with a post processing which copies the file in a MVS data set and
removes the copied file from USS on success.
------------------------------------------------------------------------
flcl xcnv
input(save.file(fio.blk(file=wrtorg.bin)))
output(save.file(
fio.blk(file=ssh://:limes@zos22/wrtorg.bin
pstpro(command='cp -B [copy] "//TEST.XMIT([base])"')
pstpro(command='rm [copy]' on=success))))
------------------------------------------------------------------------
The two usecases are a copy of our manual. The Pre- and Post-Processing is primarily used for process integration and automation.